安装pyinstaller
命令行cd切换到程序.py所在的目录
pyinstaller –console –onefile 程序.py
安装pyinstaller
命令行cd切换到程序.py所在的目录
pyinstaller –console –onefile 程序.py
a = dist(25).zip
b = a.replace("(","").relpace(")","")
**************************************************************
import sys, os
#win环境判断传入参数是单文件名/带完整路径的文件名,并做处理
arg = sys.argv[1]
sourceDir = "d:\\tmp\\"
if arg.find("\\") > 0:
packageName = os.path.basename(arg)
sourceFile = arg
else:
packageName = arg
sourceFile = sourceDir + packageName
packageNewName = packageName.replace('(','').replace(')','')
sourceFile = sourceFile.replace("\\","\\\\")
print(packageName, packageNewName)
print(sourceFile)rename_package(){
##删除文件名中的()
newname=echo $my_deploy_file | sed 's/[(|)]//g'
mv $my_deploy_file $newname
}
#调用
rename_package
# encoding='utf-8'
from fabric import Connection
import sys
from fabric import Connection
import sys
packageName = sys.argv[1].replace('(','').replace(')','')
sourceDir = "C:\\tmp\\"
destDir = "/usr/local/src/"
with Connection(host="122.226.107.154", port=2024, user="root", connect_kwargs={"password":"xxxx"}) as c:
c.put(sourceDir + sys.argv[1], destDir + packageName)
c.run('rm -rf /usr/local/src/dist')
c.run('rm -rf /usr/local/app/szzj-portal-pc/*')
c.run('unzip -o /usr/local/src/%s -d /usr/local/src/' %(packageName))
c.run('/usr/bin/mv -f /usr/local/src/dist/* /usr/local/app/szzj-portal-pc/')fabric 官网已经更新到2.6版,阿里镜像下载也已经是2.5的版本,但是网络上搜索到的案例大部分是按照1.X版本编写的。今天查看了下官网的文档,一些用法记录下。
fabric.connection.Connection 这个类是从 Invoke 的Context 继承过来的,另外它还封装了Paramiko SSHClient 。可用参数如下:Connection(host, user=None, port=None, config=None, gateway=None, forward_agent=None, connect_timeout=None, connect_kwargs=None, inline_ssh_env=None)
这里主要说明下connect_kwargs这个参数,它的值是字典(dict),比如密码,密钥key只能设置在这里。这个字典会直接传递给paramiko.client.SSHClient.connect解析,完整的可用字段如下:connect(hostname, port=22, username=None, password=None, pkey=None, key_filename=None, timeout=None, allow_agent=True, look_for_keys=True, compress=False, sock=None, gss_auth=False, gss_kex=False, gss_deleg_creds=True, gss_host=None, banner_timeout=None, auth_timeout=None, gss_trust_dns=True, passphrase=None, disabled_algorithms=None)
fabric.group.Group(*hosts, **kwargs)fabric.group.SerialGroup(*hosts, **kwargs) fabric.group.ThreadingGroup(*hosts, **kwargs)因为本机测试不支持put (2.5版本)。group.py也看了,确实没有put ,不好用。
还是选择了for 循环IP列表调用Connection 来实现多主机操作。
1、参数传递 :
python 的参数传递到 shell 脚本 c.run('/root/test.sh %s' %(sys.argv[1]))
实现上类是print函数传参。
修改文件/etc/security/limits.conf,在文件尾部添加如下代码(如果已经存在则修改相应数值):
root soft nofile 65535
root hard nofile 65535
* soft nofile 65535
* hard nofile 65535注:只配置最后两行不就可以了吗,为啥还要单独为root用户配置呢?查了网上资料,说是*这样的通配符对root用户无效,所以root需要单独配置(嗯,阿里云ECS就配置了上面这4行)。
修改配置文件 /etc/my.cnf
[mysqld] log-bin=mysql-bin #开启二进制日志 server-id=1 #设置server-id
重启mysql,登录mysql控制台,创建用于同步的用户账号:
mysql> CREATE USER 'repl'@'123.57.44.85' IDENTIFIED BY 'slavepass';#创建用户
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'123.57.44.85';#分配权限
mysql> flush privileges; #刷新权限查看master状态,记录二进制文件名(mysql-bin.000003)和位置(73):
mysql > SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000003 | 73 | test | manual,mysql |
+------------------+----------+--------------+------------------+同样找到my.cnf配置文件,添加server-id
[mysqld]
server-id=2 #设置server-id,必须唯一重启mysql,打开mysql会话,执行同步SQL语句(需要主服务器主机名,登陆凭据,二进制文件的名称和位置):
mysql> CHANGE MASTER TO
-> MASTER_HOST='182.92.172.80',
-> MASTER_USER='rep1',
-> MASTER_PASSWORD='slavepass',
-> MASTER_LOG_FILE='mysql-bin.000003',
-> MASTER_LOG_POS=73;启动slave同步进程
mysql>start slave;查看slave状态:
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 182.92.172.80
Master_User: rep1
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000013
Read_Master_Log_Pos: 11662
Relay_Log_File: mysqld-relay-bin.000022
Relay_Log_Pos: 11765
Relay_Master_Log_File: mysql-bin.000013
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB: 当Slave_IO_Running和Slave_SQL_Running都为YES的时候就表示主从同步设置成功了
binlog-do-db:指定mysql的binlog日志记录哪个db
Replicate_Do_DB:参数是在slave上配置,指定slave要复制哪个库
在master上设置binlog_do_弊端:
1、过滤操作带来的负载都在master上
2、无法做基于时间点的复制(利用binlog)。
需要注意的是最好在从服务器的my.cnf里设置read_only选项,防止发生意外(连接用户不能有SUPER权限,否则无效)。
记得先手动同步一下主从服务器:
先在主服务器上锁定所有的表,以免在复制过程中数据发生变化:mysql> flush tables with read lock;
然后在主服务器上查询当前二进制文件的文件名及偏移位置:mysql > show master status;
然后停止主服务器上的MySQL服务:shell> mysqladmin -u root shutdown
注意:如果仅是MyISAM的话,可以不停止MySQL服务,但要在复制数据文件的过程中保持只读锁,如果是InnoDB的话,必须停止MySQL服务。
再拷贝数据文件:shell> tar -cvf /tmp/mysql-snapshot.tar .
拷贝完别忘了启动主服务上的MySQL服务了。
然后把数据文件应用到从服务器上,再次启动slave的时候使用,记得启动时加上skip-slave-start选项,使之不会立刻去连接master,再在从服务器上设置相关的二进制日志信息:
mysql> CHANGE MASTER TO
-> MASTER_HOST='master_host_name',
-> MASTER_USER='replication_user_name',
-> MASTER_PASSWORD='replication_password',
-> MASTER_LOG_FILE='recorded_log_file_name',
-> MASTER_LOG_POS=recorded_log_position;启动从服务器上的复制线程:mysql> start slave;
验证主从设置是否已经成功:mysql> show slave status\G;
关系型数据库,是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库中的数据。
主流的 oracle、DB2、MS SQL Server 和 mysql 都属于这类传统数据库。
NoSQL 数据库,全称为 Not Only SQL,意思就是适用关系型数据库的时候就使用关系型数据库,不适用的时候也没有必要非使用关系型数据库不可,可以考虑使用更加合适的数据存储。主要分为
每种 NoSQL 都有其特有的使用场景及优点。
•Git Flow是一套使用Git进行源代码管理时的一套行为规范
•Git Flow是构建在Git之上的一个组织软件开发活动的模型,是在Git之上构建的一项软件开发最佳实践
•Git Flow重点解决的是由于源代码在开发过程中的各种冲突导致开发活动混乱的问题
•Git Flow通过创建和管理分支,为每个分支设定具有特定的含义名称,并将软件生命周期中的各类活动归并到不同的分支上。实现了软件开发过程不同操作的相互隔离
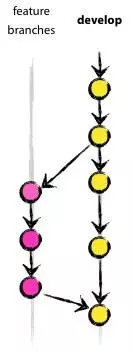
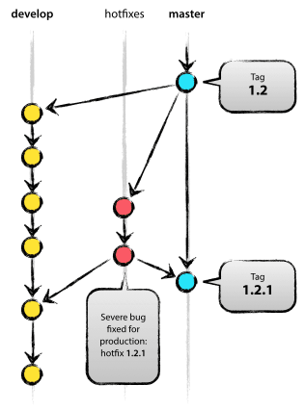
•master:随时可供在生产环境中部署的代码的分支
•develop:保存当前最新开发成果的分支
接到一个新的功能的开发任务后,从develop分支发起,并push成为远程分支
命名规范:例如开发一个项目信息的功能,则创建的分支名为:feature-project-info
每天下班前push代码到远程,进行备份,防止本地电脑故障导致代码丢失。一般feature分支由单人开发维护,可视为个人分支,所以push的代码不稳定也不会影响他人
每个人只需要维护好自己的功能分支,无需与他人进行频繁的合并,极大的降低了冲突概率,降低了代码互相覆盖的风险,从而实现多人多功能的并行开发
若不同的feature分支之间有依赖关系,则等目标feature分支开发完成以后,直接pull目标feature分支即可,若需要协同开发,则多人使用同一条feature分支即可
功能相关的代码开发完毕,并通过自测稳定以后,合并回develop分支,并可以删除feature分支,feature分支的生命周期到此结束
注意事项:所有merge操作,必须使用–no-ff参数禁止fast forward合并,防止丢失合并历史信息,例:git merge –no-ff feature-project-info
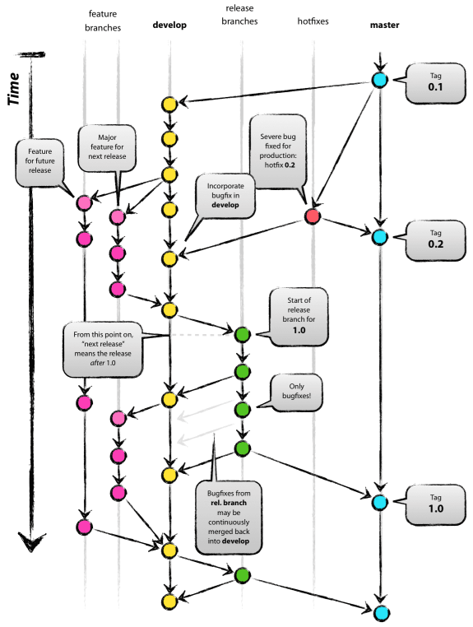
•release分支是为发布新版本提供支持的分支,从最新的develop分支发起(已合并所有此次要上线的feature) •命名规范:一般以发布日期为分支名,如7月15日计划上线,则分支名为:release-0715或release-7.15 •发布测试环境应拉取此分支的代码进行打包(结合jenkins自动化部署) •测试中发现的bug,也直接在此分支进行修复,与可能还在往前演进的develop分支隔离并行,控制发布的代码范围,防止多余的功能代码被意外的发布上线 •测试通过后,由开发经理合并到master(master分支受保护,合并需要权限),然后使用master的代码进行打包,发布生产环境,发布后,并打上版本号的tag •发布上线后,需要将master合并回develop,将release分支中修改的bug同步,防止bug重现
•多版本上线时间相近,并且需要进行功能点隔离时
•创建多条release分支,不同的公共集成feature分支直接合并到对应的release分支上
•而不是全部合并到develop分支上,从而达到不同的发布版本功能范围隔离的效果
硬件需求: